
Compiling Ruby. Part 2: RiteVM
Published on
This article is part of the series "Compiling Ruby," in which I'm documenting my journey of building an ahead-of-time (AOT) compiler for DragonRuby, which is based on mruby and heavily utilizes MLIR and LLVM infrastructure.
This series is mostly a brain dump, though sometimes I'm trying to make things easy to understand. Please, let me know if some specific part is unclear and you'd want me to elaborate on it.
Here is what you can expect from the series:
- Motivation: some background reading on what and why
- Compilers vs Interpreters: a high level overview of the chosen approach
- RiteVM: a high-level overview of the mruby Virtual Machine
- MLIR and compilation: covers what is MLIR and how it fits into the whole picture
- Progress update: short progress update with what's done and what's next
- Exceptions: an overview of how exceptions work in Ruby
- Garbage Collection (TBD): an overview of how mruby manages memory
- Fibers (TBD): what are fibers in Ruby, and how mruby makes them work
mruby (so-called “embedded” Ruby) is a relatively small Ruby implementation.
mruby is based on a register-based virtual machine. In the previous article, I mentioned the difference between stack- and register-based VMs, but what is a Virtual Machine? As obvious as it gets, a Virtual Machine is a piece of software that mimics specific behavior(s) of a Real Machine.
Depending on the kind of virtual machine, the capabilities may vary. A VM can mimic a typical computer’s complete behavior, allowing us to run any software we’d run on a regular machine (think VirtualBox or VMware). Or it can implement a behavior of an imaginary, artificial machine that doesn’t have a counterpart in the real physical world (think JVM or CLR).
The mruby RiteVM is of a latter kind. It defines a set of “CPU” operations and provides a runtime to run them. The operations are referred to as bytecode. The bytecode consists of an operation kind (opcode) and its corresponding metadata (registers, flags, etc.).
Bytecode
Here is a tiny snippet of various RiteVM operations (coming from mruby/ops.h):
OPCODE(NOP, Z) /* no operation */
OPCODE(MOVE, BB) /* R(a) = R(b) */
OPCODE(ADD, B) /* R(a) = R(a)+R(a+1) */
OPCODE(ENTER, W) /* arg setup according to flags (23=m5:o5:r1:m5:k5:d1:b1) */
OPCODE(JMP, S) /* pc+=a */
All the opcodes follow the same form:
OPCODE(name, operands) /* comment */
The name is self-explanatory. The comment describes (or hints at) an operation’s semantics.
The operands is a bit more tricky and is directly related to the bytecode encoding.
Each letter in the operands describes the size of the operand. Z means that the operand’s size is zero bytes (i.e., there is no operand).
B, S, and W all mean one operand, but their sizes are 1, 2, and 3 bytes, respectively.
These definitions can be mixed and matched as needed, but in practice, only the following combinations are used (from mruby/ops.h):
/* operand types:
+ BB: 8+8bit
+ BBB: 8+8+8bit
+ BS: 8+16bit
+ BSS: 8+16+16bit
*/
as the operation may have up to three operands max.
The operands are called a, b, and c. The following bytecode string will be decoded differently depending on the operand definition (the 42 will be mapped to a corresponding opcode):
42 1 2 3
BBB->a = 1, b = 2, c = 3B->a = 1, b = undefined, c = undefined,2is treated as the next opcodeBS->a = 1, b = 2 << 8 | 3, c = undefinedW->a = 1 << 16 | 2 << 8 | 3, b = undefined, c = undefined- and so on.
Now the comments from the snippet above make more sense:
NOPdoes nothing with all its zero operandsMOVEcopies value from registerbto registeraENTERmaps the operandato the flags needed for its logicJMPchanges the program counter to point to a new locationb
With all this information, we now understand what the operations do. The next question is how do they do it?
Bytecode Execution
The bytecode doesn’t live in a vacuum. Each bytecode sequence is part of a method. Consider the following example:
def sum(a, b)
a + b
end
puts sum(10, 32)
We can look into its bytecode:
> mruby --verbose sum.rb
<skipped>
irep 0x600001390000 nregs=6 nlocals=1 pools=0 syms=2 reps=1 ilen=25
file: sum.rb
1 000 TCLASS R1
1 002 METHOD R2 I(0:0x600001390050)
1 005 DEF R1 :sum
4 008 LOADI R3 10
4 011 LOADI R4 32
4 014 SSEND R2 :sum n=2 (0x02)
4 018 SSEND R1 :puts n=1 (0x01)
4 022 RETURN R1
4 024 STOP
irep 0x600001390050 nregs=7 nlocals=4 pools=0 syms=0 reps=0 ilen=14
local variable names:
R1:a
R2:b
R3:&
file: sum.rb
1 000 ENTER 2:0:0:0:0:0:0 (0x80000)
2 004 MOVE R4 R1 ; R1:a
2 007 MOVE R5 R2 ; R2:b
2 010 ADD R4 R5
2 012 RETURN R4
The bytecode sequence is part of the mrb_irep struct, which is subsequently part of the RProc struct, which corresponds to a Ruby method (procedure?) object.
The distinction is necessary as RProc is a higher-level abstraction over an executable code, which might be either a RiteVM bytecode or a C function. Additionally, there is a distinction between a lambda, a block, and a method. Yet, we will only focus on the bytecode parts and ignore all the lambda/block/method shenanigans.
In the previous article, I briefly described the dispatch loop and how a VM interacts with the virtual stack. The description is not precise but accurate and catches the essential details.
Execution of each RProc requires a virtual stack to operate on the data, but it also requires some additional metadata. The “metadata” is part of the so-called mrb_callinfo struct. This concept is known as stack frame or activation record.
The virtual stack is stored separately but is part of the mrb_callinfo (sort of).
The virtual stack is essential as it is the only way to communicate between different operations and different RProcs.
Here is what happens during bytecode execution:
mrb_callinfois created from anRProcand is put onto the “call info” stack or simply a call stack. The newmrb_callinfopoints to a new location of the shared virtual stack (see the first picture below).- Each operation in
RProc’smrb_irepis executed in the context of the topmrb_callinfoon the call stack. The virtual stack and state of the VM are updated accordingly. - When any “sendable” (
OP_SEND,OP_SSEND,OP_SENDBV, etc.) operation is encountered, we move to step 1. - When any “returnable” (
OP_RETURN,OP_RETURN_BLK) operation is encountered, then the operand is put into the “return register” (for consumption by the caller), and the call stack is popped, effectively removingmrb_callinfocreated at step 1.
Here is how it looks in memory:
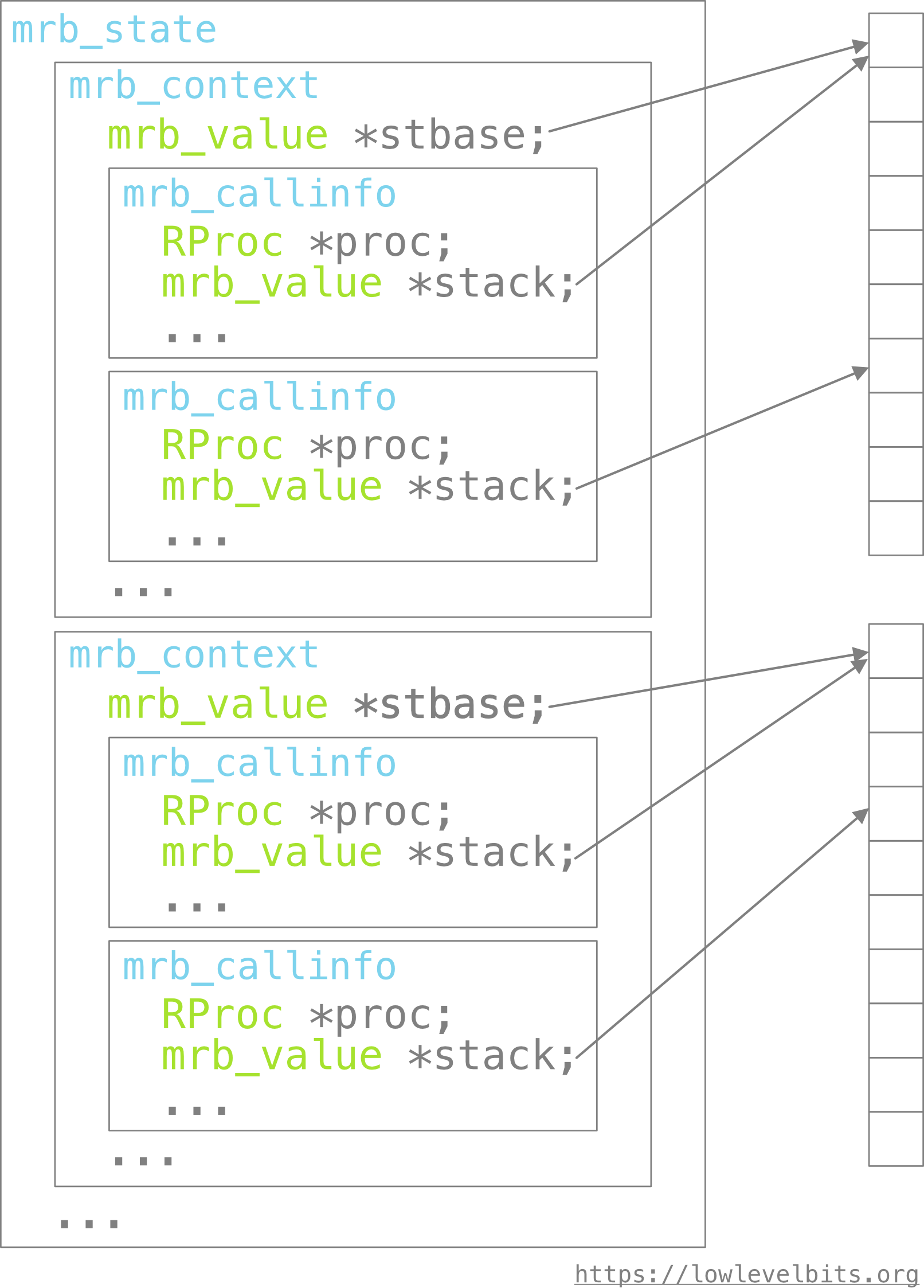
mrb_state (the state of the whole VM) has a stack of mrb_contexts (more on them in a later article). Each mrb_context maintains the stack of mrb_callinfo (the call stack). Each mrb_context owns a virtual stack, which is shared among several mrb_callinfo.
This way, the caller prepares the stack for the callee.
As a reminder, here is the bytecode from the example above:
top:
TCLASS R1
METHOD R2 I(0:0x600001390050)
DEF R1 :sum
LOADI R3 10
LOADI R4 32
SSEND R2 :sum n=2 (0x02)
SSEND R1 :puts n=1 (0x01)
RETURN R1
STOP
sum:
ENTER 2:0:0:0:0:0:0 (0x80000)
MOVE R4 R1 ; R1:a
MOVE R5 R2 ; R2:b
ADD R4 R5
RETURN R4
This is how the shared stack looks from the perspective of both the top-level method top and the method sum: by the time the first SSEND operand (“send to self”) is executed, all the values are ready for consumption by the callee.

Hopefully, now you better understand how RiteVM uses bytecode, and we are one step closer to the actual fun part - compilation!
The following article covers MLIR and the way I modeled dialects - MLIR and compilation