
Compiling Ruby. Part 1: Compilers vs. Interpreters
Published on
This article is part of the series "Compiling Ruby," in which I'm documenting my journey of building an ahead-of-time (AOT) compiler for DragonRuby, which is based on mruby and heavily utilizes MLIR and LLVM infrastructure.
This series is mostly a brain dump, though sometimes I'm trying to make things easy to understand. Please, let me know if some specific part is unclear and you'd want me to elaborate on it.
Here is what you can expect from the series:
- Motivation: some background reading on what and why
- Compilers vs Interpreters: a high level overview of the chosen approach
- RiteVM: a high-level overview of the mruby Virtual Machine
- MLIR and compilation: covers what is MLIR and how it fits into the whole picture
- Progress update: short progress update with what's done and what's next
- Exceptions: an overview of how exceptions work in Ruby
- Garbage Collection (TBD): an overview of how mruby manages memory
- Fibers (TBD): what are fibers in Ruby, and how mruby makes them work
With the (hopefully) convincing motivation out of the way, we can get to the technical details.
Compiling Interpreter, Interpreting Compiler
As mentioned in the motivation, I want to build an ahead-of-time compiler for Ruby. I want it to be compatible with the existing Ruby implementation to fit it naturally into the existing system.
So the first question I had to answer is - how do I even do it?
Compilers vs. Interpreters
The execution model of compiled and interpreted languages is slightly different:
-
a compiler takes the source program and outputs another program that can be run on any other machine even when the compiler is not on that target machine
-
an interpreter also takes the source program as an input but does not output anything and runs the program right away
Unlike the compiler, the interpreter must be present on the machine you want to run the program. To build the compiler, I have to somehow combine the interpreter with the program it runs.
Let’s take a high-level schematic view of a typical compiler and interpreter.
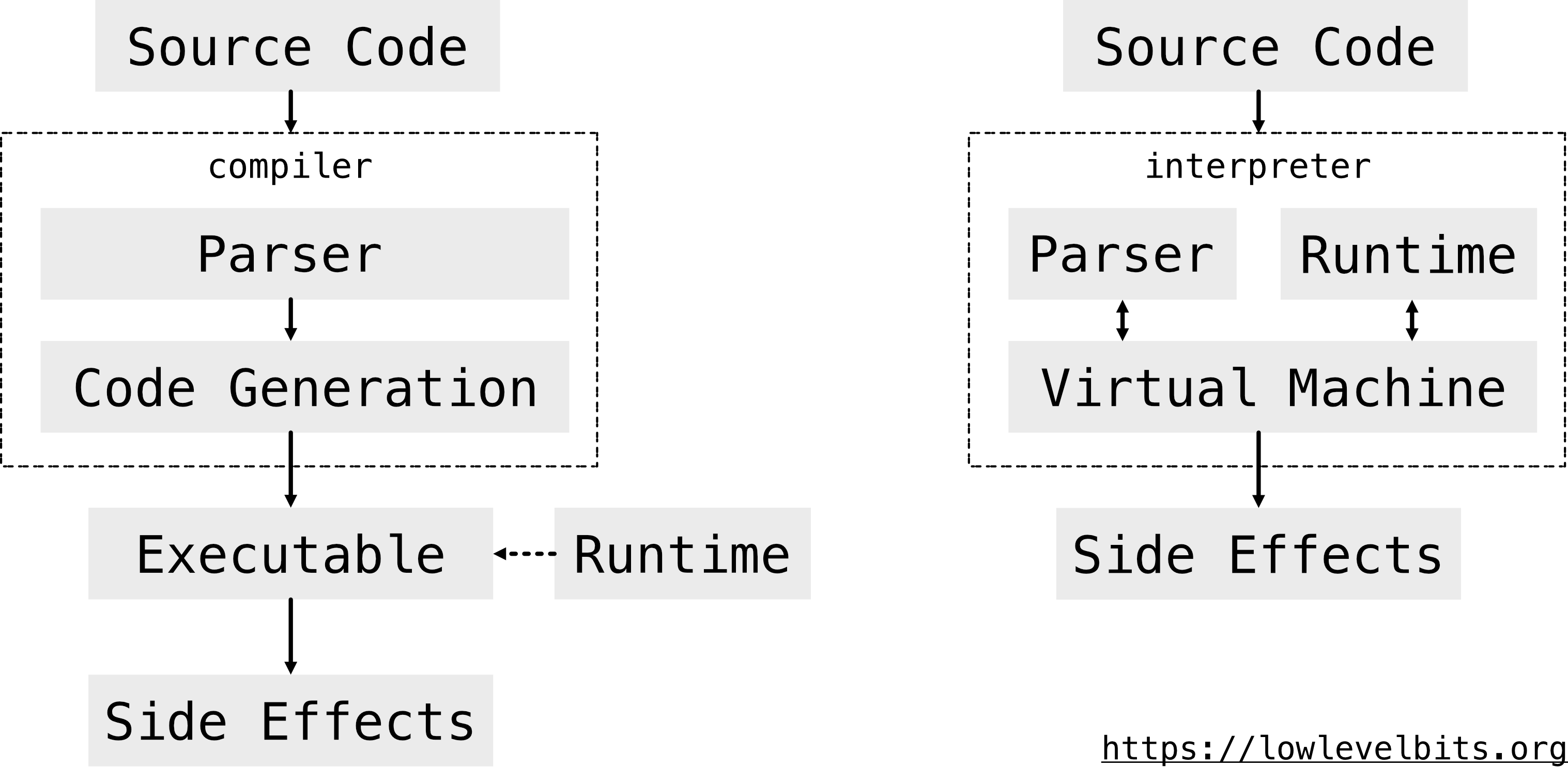
The compiler is a straightforward one-way process: the source code is parsed, then the machine code is generated, and the executable is produced. The executable also depends on a runtime. The runtime can be either embedded into the executable or be an external entity, but usually both.
The interpreter is more complex in this regard. It contains everything in one place: parser, runtime, and a virtual machine. Also, note the two-way arrows Parser <-> VM and Runtime <-> VM. The reason is that Ruby is a dynamic language. During the regular program execution, a program can read more code from the disk or network and execute it, thus the interconnection between these components.
Parser + VM + Runtime
Arguably, the triple VM + Parser + Runtime can be called “a runtime,” but I prefer to have some separation of concerns. Here is where I draw the boundaries:
- Parser: only does the parsing of the source code and converts it into a form suitable for execution via the Virtual Machine (“bytecode”)
- Virtual Machine: the primary “computational device,” it operates on the bytecode and actually “runs” the program
- Runtime: machinery required by the parser and VM (e.g., VM state manipulation, resource management, etc.)
A naïve approach to building the compiler is to tear the interpreter apart: replace VM and runtime with codegen and embed the runtime into the resulting executable. However, the runtime extraction won’t work due to the dynamism mentioned above - the resulting executable should be able to parse and run any arbitrary Ruby code.
Side note: an alternative approach is to build a JIT compiler and embed the whole compiler into the executable, but it adds more complexity than I am ready to deal with.
In the end, the solution is simpler - the compiler and the final executable include the whole interpreter. So the final “compiling interpreter” (or “interpreting compiler”) looks like this:

Ruby and its many Virtual Machines
Now it’s time to discuss the Virtual Machine component.
The most widely used Ruby implementation is CRuby, also known as MRI (as in “Matz’ Ruby Interpreter”). It is an interpreter built on top of a custom virtual machine (YARV).
Another widely used implementation is mruby (so-called “embedded” Ruby). It is also an interpreter and built on top of another custom VM (RiteVM).
YARV and RiteVM are rather lightweight virtual machines. Unlike full-fledged system or process-level VMs (e.g., VirtualBox, JVM, CLR, etc.), they only provide a “computational device” - there is no resource control, sandboxing, etc.
Stack vs. Registers
The “computational device” executes certain operations on certain data. The operations are encoded in the form of a “bytecode.” And the data is stored on a “virtual stack”. Though, the stack is accessed differently.
YARV accesses the stack implicitly (this is also known as a “stack-based VM”). RiteVM accesses the stack explicitly via registers (you got it, “register-based VM”).
To illustrate the bytecode and the difference between YARV and RiteVM, consider the following artificial examples.
Stack-based bytecode:
load 10
load 32
plus
print
Register-based bytecode:
load R1 10
load R2 32
plus R1 R1 R2
print R1
The stack-based version uses the stack implicitly, while another version specifies the storage explicitly.
Let’s “run” both examples to see them in action.

At every step, the VM does something according to the currently running instruction/opcode (underscored lines) and updates the virtual stack.
Stack-based VM only reads/writes data from/to the place where an arrow points to - this is the top of the virtual stack.
Register-based VM does the same but has random access to the virtual stack.
While the underlying machinery is very similar, there are good reasons for picking one or the other form of a VM. Yet, these reasons are out of the scope of this series. Please, consult elsewhere if you want to learn more. The topic of VMs is huge but fascinating.
Dispatch loop
Let’s consider how the VM works and deals with the bytecode.
YARV and RiteVM use the so-called “dispatch loop,” which is effectively a for-loop + a huge switch-statement. Typical pseudocode looks like this:
// Iterate through each opcode in the bytecode stream
for (opcode in bytecode) {
switch (opcode) {
// Take a corresponding action for each separate opcode
case OP_CODE_1: /* do something */;
case OP_CODE_2: /* do something */;
// ... more opcodes
case OP_CODE_N: /* do something */;
}
}
And then, the bodies for the actual opcodes may look as follows. Stack-based VM:
/*
Example program:
load 10
load 32
plus
print
*/
case OP_LOAD:
val = pool[0] // pool is some abstract additional storage
stack.push(val)
case OP_PLUS:
lhs = stack.pop()
rhs = stack.pop()
res = lhs + rhs
stack.push(res)
case OP_PRINT:
val = stack.pop()
print(val)
And the register-based version for completeness:
/*
Example program:
load R1 10
load R2 32
plus R1 R1 R2
print R1
*/
// md is some additional opcode metadata
case OP_LOAD:
registers[md.reg1] = pool[0]
case OP_PLUS:
lhs = registers[md.reg1]
rhs = registers[md.reg2]
res = lhs + rhs
registers[md.reg1] = res
case OP_PRINT:
val = registers[md.reg1]
print(val)
In this case, if we know the values behind pool[0] and the actual values of md.regN, then we compile the example program to something like this:
/*
load R1 10
load R2 32
plus R1 R1 R2
print R1
*/
R1 = 10
R2 = 32
R1 = R1 + R2
print(R1)
and avoid the whole dispatch loop, but I digress :)
In the following article, we look into mruby’s implementation and virtual machine in more detail - Compiling Ruby. Part 2: RiteVM.