
Handling timeouts in child processes
Published on
Building a tool for mutation testing has many challenges in it. Sandboxing is one of them. We do trust the original code of a program, but we cannot trust the mutated code: a mutant can crash or just run into an infinite loop. The most obvious solution for this problem is to run this code in a child process and limit its execution time.
In this article, I want to describe several approaches on how to handle timeouts in child processes. Please, let me know if you see any flaws in these solutions.
Timer, Worker, and Watchdog
I have found one of the solutions on the internet. I find it very elegant!
The parent process, the watchdog, forks two processes: timer and worker.
Timer sleeps for some time, while the worker does its job.
Watchdog is waiting for either of those to finish. If timer finishes first,
then the worker is timed out. And vice versa.
Here is an illustration of this idea:
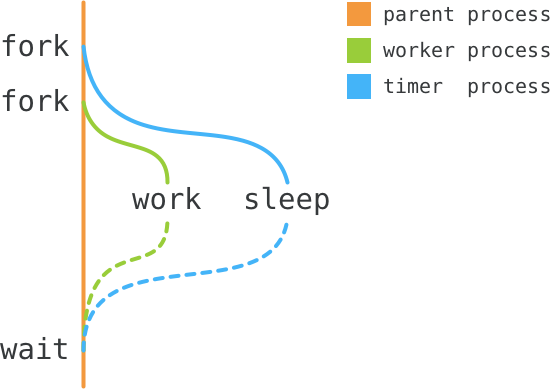
It looks very straightforward, but there are few more details when it comes to the implementation. Let’s look at them (full code listing is available online).
typedef void (*work_t)(void);
void watchdog_worker_timer(work_t work, long long timeout) {
const pid_t timer_pid = fork();
if (timer_pid == -1) {
perror("fork timer");
abort();
}
if (timer_pid == 0) {
/// Timer process
usleep(timeout * 1000);
exit(0);
}
const pid_t worker_pid = fork();
if (worker_pid == -1) {
perror("fork worker");
abort();
}
if (worker_pid == 0) {
/// Worker process
work();
exit(0);
}
int status = 0;
const pid_t finished_first = waitpid_eintr(&status);
if (finished_first == timer_pid) {
printf("timed out\n");
kill(worker_pid, SIGKILL);
} else if (finished_first == worker_pid) {
printf("all good\n");
kill(timer_pid, SIGKILL);
} else {
assert(0 && "Something went wrong");
}
waitpid_eintr(&status);
}
This function does exactly what is described above. It takes a pointer to a function that does the actual work and sets a timeout.
The tricky part, however, is the call to waitpid_eintr. Here is the body:
pid_t waitpid_eintr(int &status) {
pid_t pid = 0;
while ( (pid = waitpid(WAIT_ANY, status, 0)) == -1 ) {
if (errno == EINTR) {
continue;
} else {
perror("waitpid");
abort();
}
}
return pid;
}
Call to waitpid can fail for many reasons. One of them that is likely to happen is EINTR, or ‘interrupted function call.’ You can get more details here and from the man page: man 2 intro on macOS and man 3 errno on Linux.
In our case there is no need for some special treatment - we keep calling waitpid until it succeeds or fails with some other reason.
This solution is elegant and easy to understand, though it has one disadvantage: we need to create an additional process, thus wasting system’ resources. Fortunately, there is another approach.
System timers
Which timer to use
Programs on Linux and macOS can receive a signal after some time passes. To do that a program manipulates one of the three timers provided by an operating system: real, virtual, and profiling.
But which one to pick? Look at the following illustration. For simplicity, let’s assume that each ‘brick’ takes one second to run.

Here, two processes are being run. The first one (green) does some work for a second. Then it makes a system call that takes another second. At this point, OS decides to preempt it with another (blue) process. It also does some job in the user space for a second, and then switches to the kernel space by making some heavy system call. After two seconds in the kernel, the blue process terminates. OS runs the green process for one more second, and it also terminates.
In total, it took 6 seconds to run both processes: 3 seconds for each of them.
However, according to different timers the time will be slightly different:
| Timer | Green | Blue |
|---|---|---|
| real | 6 seconds | 3 seconds |
| virtual | 2 seconds | 1 second |
| profiling | 3 seconds | 3 seconds |
Real timer, ITIMER_REAL, counts total time, you can see it as a real clock.
Virtual timer, ITIMER_VIRTUAL,
counts only time spent in the user space. And the profiling timer, ITIMER_PROF,
counts time spent both in the user space and in the kernel space.
For more information, please look at man 2 setitimer on Linux and man 3 setitimer on macOS.
You are free to use the one that fits your requirements better. However, be aware, when you call sleep() the process is preempted by OS and neither virtual nor profiling timers are counting.
How to use a timer
The algorithm is relatively trivial:
- setup the timer
- setup a signal handler
- handle the signal
- handle exit status
However, you should be aware of some pitfalls.
void handle_alarm_signal(int signal, siginfo_t *info, void *context) {
_exit(112);
}
void setup_timer(long long timeout) {
struct sigaction action;
memset(&action, 0, sizeof(action));
action.sa_sigaction = &handle_alarm_signal;
if (sigaction(SIGALRM, &action, NULL) != 0) {
perror("sigaction");
abort();
}
struct itimerval timer;
/// Get only seconds in
timer.it_value.tv_sec = timeout / 1000;
/// Cut off seconds, and convert what's left into microseconds
timer.it_value.tv_usec = (timeout % 1000) * 1000;
/// Do not repeat
timer.it_interval.tv_sec = 0;
timer.it_interval.tv_usec = 0;
if (setitimer(ITIMER_REAL, &timer, NULL) != 0) {
perror("setitimer");
abort();
}
}
void system_timers(work_t work, long long timeout) {
const pid_t worker_pid = fork();
if (worker_pid == -1) {
perror("fork worker");
abort();
}
if (worker_pid == 0) {
setup_timer(timeout);
work();
exit(144);
}
int status = 0;
waitpid_eintr(status);
if (WIFEXITED(status) && WEXITSTATUS(status) == 112) {
printf("timed out\n");
}
else if (WIFEXITED(status) && WEXITSTATUS(status) != 144) {
printf("all good\n");
}
}
system_timers function takes a pointer to a worker function and the desired timeout in milliseconds. Then, it forks a new process, the child process sets up a timer and runs the worker function. Then it handles the exit status of the worker process: this is where it gets interesting. 122 and 144 are some arbitrary numbers, but it is important to have there something that does not collide with a ’normal’ exit code. By using these exit codes, we can differentiate whether the process terminated because of timeout (122) or just because the work has finished (144).
The signal handler takes care of the SIGALRM signal because we use the real timer:
ITIMER_REAL. For ITIMER_VIRTUAL and ITIMER_PROF you should use SIGVTALRM
and SIGPROF respectively.
You may notice that handle_alarm_signal calls _exit function instead of the more familiar exit: it is done on purpose. Signal handlers are allowed to call only functions that considered as safe. When you call an unsafe function - behavior is undefined.
_exit is safe, exit is unsafe. Follow the safe way here. Believe me, you
don’t want to debug this stuff.
For the list of safe functions consult man page on your system: man sigaction.
The last point. setitimer function may look a bit verbose. In fact, there is
a shortcut: ualarm. However, you should avoid using this function. It works
excellent on macOS, but it is buggy on Linux.
macOS implementation (from macOS libc, gen/FreeBSD/ualarm.c):
struct itimerval new, old;
new.it_interval.tv_usec = reload % USPS;
new.it_interval.tv_sec = reload / USPS;
new.it_value.tv_usec = usecs % USPS;
new.it_value.tv_sec = usecs / USPS;
if (setitimer(ITIMER_REAL, &new, &old) == 0)
return (old.it_value.tv_sec * USPS + old.it_value.tv_usec);
/* else */
return (-1);
Linux implementation (from GNU libc, sysdeps/unix/bsd/ualarm.c):
struct itimerval timer, otimer;
timer.it_value.tv_sec = 0;
timer.it_value.tv_usec = value;
timer.it_interval.tv_sec = 0;
timer.it_interval.tv_usec = interval;
if (__setitimer (ITIMER_REAL, &timer, &otimer) < 0)
return -1;
return (otimer.it_value.tv_sec * 1000000) + otimer.it_value.tv_usec;
macOS’s implementation sets up the timer correctly. On Linux, it ignores seconds (tv_sec), while setitimer ignores any microseconds value (tv_usec) that is more than 1 000 000, which is one second. To put it simply: ualarm works correctly on Linux only when called with the timeout interval that is less than one second.
Summary
Both approaches have proven to be working very well.
Initially, we started with the watchdog process approach because of its simplicity. At that point, we did not care about the performance and resources that much.
Later, when it came to parallelization, we decided not to waste
resources and switched to the second approach. We had hell load amount of weird
issues: deadlocks after exit (not _exit), faulty ualarm on Linux, wrong
kind of timer, to name a few. I am still not sure if we are using it right
at the moment.
To wrap it up: if you ever decide to implement something similar, I would strongly recommend using the first approach, since it has fewer surprises.