
Parsing Mach-O files
Published on
This article describes how to parse Mach-O file and explains its format a little bit. It’s not a definitive guide, though it might be helpful if you don’t know where to start. For more information consider reading official documentation and header files provided by operating system.
What is Mach-O file
Brief description taken from Wikipedia:
Mach-O, short for Mach object file format, is a file format for executables, object code, shared libraries, dynamically-loaded code, and core dumps. A replacement for the a.out format, Mach-O offers more extensibility and faster access to information in the symbol table.
Mach-O is used by most systems based on the Mach kernel. NeXTSTEP, OS X, and iOS are examples of systems that have used this format for native executables, libraries and object code.
Mach-O format
Mach-O doesn’t have any special format like XML/YAML/JSON/whatnot, it’s just a binary stream of bytes grouped in meaningful data chunks. These chunks contain a meta-information, e.g.: byte order, cpu type, size of the chunk and so on.
Typical Mach-O file (copy of the (now removed) official documentation) consists of a three regions:
- Header - contains general information about the binary: byte order (magic number), cpu type, amount of load commands etc.
- Load Commands - it’s kind of a table of contents, that describes position of segments, symbol table, dynamic symbol table etc. Each load command includes a meta-information, such as type of command, its name, position in a binary and so on.
- Data - usually the biggest part of object file. It contains code and data, such as symbol tables, dynamic symbol tables and so on.
Here is a simplified graphical representation:

There are two types of object files on OS X: Mach-O files and Universal Binaries, also so-called Fat files. The difference between them: Mach-O file contains object code for one architecture (i386, x86_64, arm64, etc.) while Fat binaries might contain several object files, hence contain object code for different architectures (i386 and x86_64, arm and arm64, etc.)
The structure of a Fat file is pretty straightforward: fat header followed by Mach-O files:

Parse Mach-O file
OS X doesn’t provide us with any libmacho or something similar, the only thing we have here - a set of C structures defined under /usr/include/mach-o/*, hence we need to implement parsing on our own. It might be tricky, but it’s not that hard.
Memory Representation
Before we start with parsing let’s look at detailed representation of a Mach-O file. For simplicity the following object file is a Mach-O file (not a fat file) for i386 with just two data entries that are segments.

The only structures we need to represent the file:
struct mach_header {
uint32_t magic;
cpu_type_t cputype;
cpu_subtype_t cpusubtype;
uint32_t filetype;
uint32_t ncmds;
uint32_t sizeofcmds;
uint32_t flags;
};
struct segment_command {
uint32_t cmd;
uint32_t cmdsize;
char segname[16];
uint32_t vmaddr;
uint32_t vmsize;
uint32_t fileoff;
uint32_t filesize;
vm_prot_t maxprot;
vm_prot_t initprot;
uint32_t nsects;
uint32_t flags;
};
Here is how memory mapping looks like:
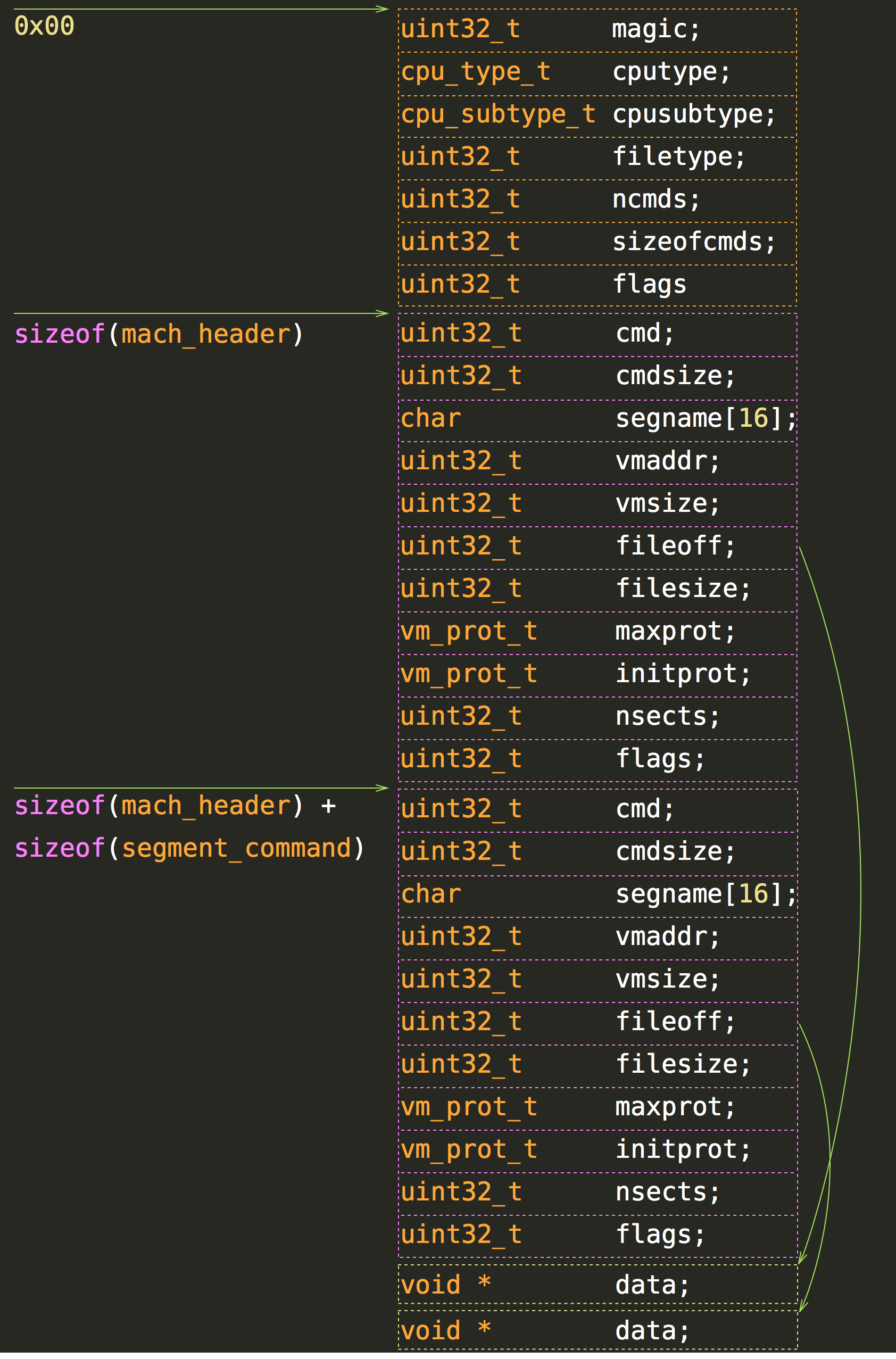
If you want to read particular info from a file, you just need a correct data structure and an offset.
Parsing
Let’s write a program that’ll read mach-o or fat file and print names of each segment and an arch for which it was built.
At the end we might have something similar:
$ ./segname_dumper some_binary
i386
segname __PAGEZERO
segname __TEXT
segname __LINKEDIT
Driver
Let’s start with a simple ‘driver’.
There are at least two possible ways to parse such files: load content into memory and work with buffer directly or open a file and jump back and forth through it. Both approaches have their own pros and cons, but I’ll stick to a second one. Also, I assume that no one going to use the program in a wrong way, hence no error handling whatsoever.
#include <stdio.h>
#include <stdlib.h>
#include <mach-o/loader.h>
#include <mach-o/swap.h>
void dump_segments(FILE *obj_file);
int main(int argc, char *argv[]) {
const char *filename = argv[1];
FILE *obj_file = fopen(filename, "rb");
dump_segments(obj_file);
fclose(obj_file);
return 0;
}
void dump_segments(FILE *obj_file) {
// Driver
}
Magic numbers, CPU and Endianness
To read at least the object file header we need to get all the information we need: CPU arch (32 bit or 64 bit) and the Byte Order. But first we need to retrieve a magic number:
uint32_t read_magic(FILE *obj_file, int offset) {
uint32_t magic;
fseek(obj_file, offset, SEEK_SET);
fread(&magic, sizeof(uint32_t), 1, obj_file);
return magic;
}
void dump_segments(FILE *obj_file) {
uint32_t magic = read_magic(obj_file, 0);
}
The function read_magic is pretty straitforward, though one thing there might look weird: fseek. The problem is that whenever somebody read from a file, the internal _offset of the file changes. It’s better to specify the offset explicitly, to ensure that we read what we actually want to read. Also, this small trick will be useful later on.
Structures that represent object file with 32 and 64 bits are different (e.g.: mach_header and mach_header_64), to choose which to use we need to check file’s architecture:
int is_magic_64(uint32_t magic) {
return magic == MH_MAGIC_64 || magic == MH_CIGAM_64;
}
void dump_segments(FILE *obj_file) {
uint32_t magic = read_magic(obj_file, 0);
int is_64 = is_magic_64(magic);
}
MH_MAGIC_64 and MH_CIGAM_64 are ‘magic’ numbers provided by the system. Second one looks even more magicly than first one. Explanation is following.
Due to historical reasons different computers might use different byte order: Big Endian (left to right) and Little Endian (right to left). Magic numbers store this information as well: MH_CIGAM and MH_CIGAM_64 says that byte order differs from host OS, hence all the bytes should be swapped:
int should_swap_bytes(uint32_t magic) {
return magic == MH_CIGAM || magic == MH_CIGAM_64;
}
void dump_segments(FILE *obj_file) {
uint32_t magic = read_magic(obj_file, 0);
int is_64 = is_magic_64(magic);
int is_swap = should_swap_bytes(magic);
}
Mach-O Header
Finally we can read mach_header. Let’s first introduce generic function for reading data from a file.
void *load_bytes(FILE *obj_file, int offset, int size) {
void *buf = calloc(1, size);
fseek(obj_file, offset, SEEK_SET);
fread(buf, size, 1, obj_file);
return buf;
}
Note: The data should be freed after usage!
void dump_mach_header(FILE *obj_file, int offset, int is_64, int is_swap) {
if (is_64) {
int header_size = sizeof(struct mach_header_64);
struct mach_header_64 *header = load_bytes(obj_file, offset, header_size);
if (is_swap) {
swap_mach_header_64(header, 0);
}
free(header);
} else {
int header_size = sizeof(struct mach_header);
struct mach_header *header = load_bytes(obj_file, offset, header_size);
if (is_swap) {
swap_mach_header(header, 0);
}
free(header);
}
free(buffer);
}
void dump_segments(FILE *obj_file) {
uint32_t magic = read_magic(obj_file, 0);
int is_64 = is_magic_64(magic);
int is_swap = should_swap_bytes(magic);
dump_mach_header(obj_file, 0, is_64, is_swap);
}
Here we introduced another function dump_mach_header to not mess up ‘driver’ function.
The next step is to read all segment commands and print their names.
The problem is that mach-o files usually contain other commands as well. If you recall the first field of segment_command structure is a uint32_t cmd;, this field represents type of a command.
Here is another structure provided by the system that we’ll use:
struct load_command {
uint32_t cmd;
uint32_t cmdsize;
};
Besides all the information mach_header has number of load commands, so we can just iterate over and skip commands we’re not interested in. Also, we need to calculate offset where the header ends. Here is the final version of dump_mach_header:
void dump_mach_header(FILE *obj_file, int offset, int is_64, int is_swap) {
uint32_t ncmds;
int load_commands_offset = offset;
if (is_64) {
int header_size = sizeof(struct mach_header_64);
struct mach_header_64 *header = load_bytes(obj_file, offset, header_size);
if (is_swap) {
swap_mach_header_64(header, 0);
}
ncmds = header->ncmds;
load_commands_offset += header_size;
free(header);
} else {
int header_size = sizeof(struct mach_header);
struct mach_header *header = load_bytes(obj_file, offset, header_size);
if (is_swap) {
swap_mach_header(header, 0);
}
ncmds = header->ncmds;
load_commands_offset += header_size;
free(header);
}
dump_segment_commands(obj_file, load_commands_offset, is_swap, ncmds);
}
Segment Command
It’s time to dump all segment names:
void dump_segment_commands(FILE *obj_file, int offset, int is_swap, uint32_t ncmds) {
int actual_offset = offset;
for (int i = 0; i < ncmds; i++) {
struct load_command *cmd = load_bytes(obj_file, actual_offset, sizeof(struct load_command));
if (is_swap) {
swap_load_command(cmd, 0);
}
if (cmd->cmd == LC_SEGMENT_64) {
struct segment_command_64 *segment = load_bytes(obj_file, actual_offset, sizeof(struct segment_command_64));
if (is_swap) {
swap_segment_command_64(segment, 0);
}
printf("segname: %s\n", segment->segname);
free(segment);
} else if (cmd->cmd == LC_SEGMENT) {
struct segment_command *segment = load_bytes(obj_file, actual_offset, sizeof(struct segment_command));
if (is_swap) {
swap_segment_command(segment, 0);
}
printf("segname: %s\n", segment->segname);
free(segment);
}
actual_offset += cmd->cmdsize;
free(cmd);
}
}
This function doesn’t need is_64 parameter, because we can infer it from cmd type itself (LC_SEGMENT/LC_SEGMENT_64). If it’s not a segment, then we just skip the command and move forward to the next one.
CPU name
The last thing I want to show is how to retrieve the name of a processor based on a cputype from mach_header.
I believe this is not the best option, but it’s acceptable for this artificial example:
struct _cpu_type_names {
cpu_type_t cputype;
const char *cpu_name;
};
static struct _cpu_type_names cpu_type_names[] = {
{ CPU_TYPE_I386, "i386" },
{ CPU_TYPE_X86_64, "x86_64" },
{ CPU_TYPE_ARM, "arm" },
{ CPU_TYPE_ARM64, "arm64" }
};
static const char *cpu_type_name(cpu_type_t cpu_type) {
static int cpu_type_names_size = sizeof(cpu_type_names) / sizeof(struct _cpu_type_names);
for (int i = 0; i < cpu_type_names_size; i++ ) {
if (cpu_type == cpu_type_names[i].cputype) {
return cpu_type_names[i].cpu_name;
}
}
return "unknown";
}
OS X provides CPU_TYPE_* for a lot of CPUs, so we can ’easily’ associate particular magic number with a string literal. To print name of a CPU we need to modify dump_mach_header a bit:
int header_size = sizeof(struct mach_header_64);
struct mach_header_64 *header = load_bytes(obj_file, offset, header_size);
if (is_swap) {
swap_mach_header_64(header, 0);
}
ncmds = header->ncmds;
load_commands_offset += header_size;
printf("%s\n", cpu_type_name(header->cputype)); // <-
free(header);
Fat objects
The article is already way too big, so I’m not going to describe how to handle Fat objects, but you can find implementation here: segment_dumper
What’s next
That’s pretty much it.
Here is a set of links that might be useful if you want to dig deeper and learn more about mach-o:
- OS X ABI Mach-O File Format Reference - official documentation from Apple
- MachOView - is a visual Mach-O file browser. It provides a complete solution for exploring and in-place editing Intel and ARM binaries.
- Mach-O Executables - nice article from objc.io.
- bitcode_retriever - simple C program that retrieves Bitcode from Mach-O binaries.
- segment_dumper - source code from this article.
Happy hacking!
P.S. This is a supplementary material for the next post, which will cover ’new’ Bitcode feature from Apple.